PoC 3 — Kafka Replay 기반 Failback & 중단, 데이터 유실없이 서버 전환
🚀 WebSocket 분산 시스템 설계의 마지막 단계 (샤딩 → 정합성 → 무중단 복구)
🔍 서비스 중단 없이 WebSocket 서버를 교체하는 방법 (Kafka Replay · Drain · Failback 설계)
원본 분석 노트: GitHub에서 보기
시리즈: WebSocket 성능 개선
PoC 1: 샤딩
PoC 2: Fallback & 충돌 제어
PoC 3: Failback & Replay
요약
| 단계 | 결과 |
|---|---|
| ws-1 장애 → ws-2 자동 인수 | 이벤트 처리 지속 ✅ |
| ws-1 복구 → Kafka Replay | replayCount=3, 유실 0 ✅ |
| ws-2 Drain → 클라이언트 재연결 | 서비스 중단 없는 전환 ✅ |
- 문제: 샤딩 서버가 복구된 후 fallback 서버에서 어떻게 원복(failback) 할 것인가
- 핵심 설계: Kafka를 이벤트 로그로 활용해 장애 구간을 offset 기반으로 복구하고,
Gateway + Drain으로 클라이언트 재연결을 유도하여 무중단 서버 전환 구현
⚠️ 어떻게 이벤트 유실 없이 서버를 교체했는지 (Kafka Replay + Drain 흐름)
원본 분석 노트: GitHub에서 보기 —
배경
PoC 2에서 fallback 환경에서의 상태 정합성을 확보했다. 그런데 장애 서버가 복구되면 새로운 문제가 생긴다:
- 복구된 서버는 장애 구간의 이벤트를 놓쳤다 — 상태를 어떻게 따라잡을 것인가
- fallback 서버에서 복구 서버로 클라이언트를 어떻게 전환할 것인가 — 세션을 강제 종료하면 사용자 경험이 깨진다
WebSocket 서버는 상태를 가지는 구조이기 때문에 stateless failover만으로는 해결되지 않는다.
핵심 설계
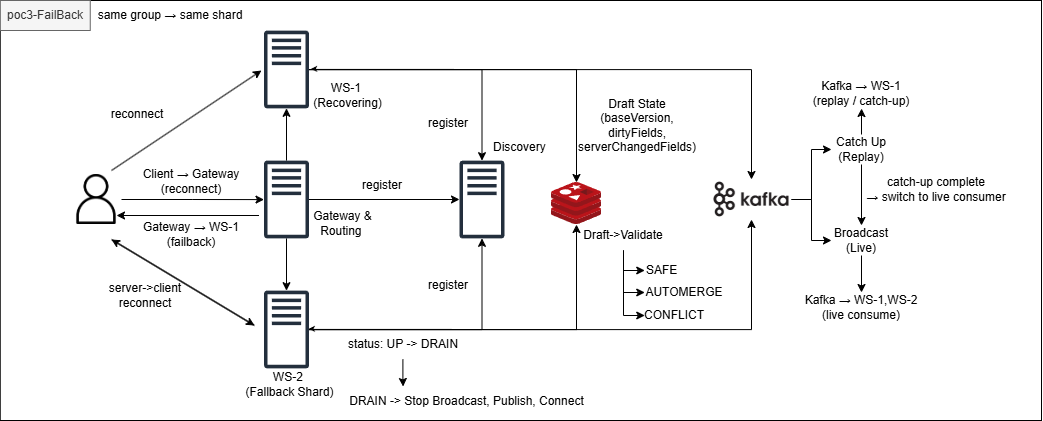
서버 상태 모델
Gateway는 각 WS 서버의 상태를 5초 주기로 polling한다.
| 상태 | 의미 |
|---|---|
| UP | 서버 alive, broadcast 준비 안 됨 |
| HEALTHY | up=true + ready=true — 정상 운영 |
| DRAINING | 종료 진행 중, 신규 연결 차단 |
| DOWN | 응답 없음 |
UP이 5회 연속 확인될 때만 복구 요청을 보낸다 (일시적 재시작 방지).
Kafka Consumer 이중화
| Consumer Group | 역할 |
|---|---|
| Broadcast | 실시간 이벤트 소비 + 브로드캐스트 |
| Catch-up | 장애 구간 replay 전용 (별도 group ID) |
두 컨테이너를 분리함으로써 replay 중에 실시간 이벤트가 오염되지 않는다.
Catch-up (Replay) 흐름
start-recovery 요청 수신
↓
현재 Kafka 최신 offset 기록 (= 따라잡을 목표)
↓
Catch-up Consumer 시작 → 과거 이벤트 순서대로 소비
↓
lastConsumedOffset == targetOffset → 완료
↓
Catch-up 종료 → ready=true → Broadcast Consumer 시작
실제 검증 로그:
[CATCHUP] raw-consume offset=0 version=0
[CATCHUP] raw-consume offset=1 version=5
[CATCHUP] raw-consume offset=2 version=6
[CATCHUP] completed replayCount=3 targetOffsets={0=2} lastConsumedOffsets={0=2}
이벤트 유실 없이 장애 구간 3건 모두 복구 확인.
🔍 Kafka offset 기반 replay 설계와 실제 복구 로그 전체 보기
원본 분석 노트: GitHub에서 보기
Drain & Failback 흐름
복구 서버(ws-1)가 HEALTHY로 전환되면 Gateway가 fallback 서버(ws-2)에 Drain을 요청한다.
Drain 요청 수신
↓
draining=true, ready=false → 신규 핸드쉐이크 차단 (503 반환)
↓
기존 세션에 재연결 요청 메시지 전송
↓
grace period(3s) 후 남은 세션 강제 종료
Drain 중 브로드캐스트 차단:
public void broadcast(CanvasEventEnvelope event) {
if (serverStateManager.isDraining()) {
log.info("[BROADCAST][SKIP][DRAIN] ...");
return; // Drain 중엔 전송하지 않음
}
...
}
실제 로그:
[SERVER_STATE] draining=true
[SERVER_STATE] ready=false
[DRAIN] started reason=FAILBACK_TO_RECOVERED_SERVER grace=3000ms
[DRAIN] reconnect notice broadcast done sessionCount=1
[DRAIN] force closing remainingSessions=0
🔍 Drain → reconnect → failback 전체 시퀀스 상세 보기
원본 분석 노트: GitHub에서 보기
전체 Failback 시퀀스 요약
[정상 운영]
ws-1 HEALTHY, ws-2 HEALTHY
Core → Kafka 발행 → ws-1 소비 (파티션 할당)
[장애 발생]
docker stop ws-1
Gateway: ws-1 = DOWN, ws-2 = HEALTHY
Kafka consumer group 재분배 → ws-2가 ws-1 파티션 인수
[ws-1 복구]
ws-1 재시작 → UP 5회 카운트 달성
Gateway → start-recovery 요청
ws-1: Catch-up Consumer 시작 → offset 0→2 replay 완료
ws-1: ready=true, Broadcast Consumer 시작
[Failback]
Gateway → ws-2에 Drain 요청
ws-2: draining=true, 신규 연결 차단, 기존 클라이언트에 재연결 요청 전송
클라이언트 → Gateway 재라우팅 → ws-1 연결
설계 선택 이유
| 결정 | 이유 |
|---|---|
| Kafka를 이벤트 로그 저장소로 사용 | 장애 구간의 이벤트를 offset 기준으로 정확히 replay 가능 |
| Gateway 중심 lifecycle orchestration | 각 서버가 독립 판단하지 않도록 → 일관성 유지 |
| Drain → reconnect 구조 | 강제 종료 없이 클라이언트가 스스로 재연결 → 사용자 경험 유지 |
| Consumer Group 분리 | Catch-up과 Broadcast가 서로 간섭하지 않음 |
핵심 인사이트
Kafka는 메시지 브로커가 아니라 이벤트 로그 저장소로 활용할 수 있다. offset 기반 replay로 장애 구간을 정확히 복구하고, Drain 구조로 클라이언트가 서비스 중단을 느끼지 않게 서버를 전환할 수 있다.