PoC 1 — WebSocket 그룹 샤딩 기반 부하 분산
📊 WebSocket 샤딩 PoC 전체 실험 과정 (부하 분산 · GC 변화 · 설계 이유)
원본 분석 노트: GitHub에서 보기
시리즈: WebSocket 성능 개선
PoC 1: 샤딩
PoC 2: Fallback & 충돌 제어
PoC 3: Failback & Replay
요약
| 항목 | 단일 인스턴스 | 샤딩 (2개) |
|---|---|---|
| totalSendAttempts | 159,317 | 79,776 + 79,759 |
| 인스턴스당 부하 | 100% | ≈50% |
| GC 횟수 (JFR) | 3회 | 각1회 |
| byte[] Allocation | 205 MiB | 93.5 + 111 MiB |
- 문제: 단일 서버에 fanout 집중 → 브로드캐스트 비용 선형 증가
- 핵심 설계: 동일 그룹을 하나의 서버로 고정시켜 fanout을 서버 내부로 제한 → broadcast 비용 자체를 분산
- 확인: 처리량 분산뿐 아니라 JVM GC/Allocation 압력도 함께 감소
⚠️ 왜 fanout이 절반으로 줄었는지 (샤딩 설계 + 실험 로그) 원본 분석 노트: GitHub에서 보기
배경
WebSocket 성능 개선에서 단일 인스턴스 기준으로 실시간성을 확보했다. 다음 단계는 동시 접속자 증가 시 수평 확장이 가능한 구조를 검증하는 것이다.
단순 라운드로빈 분산은 동일 그룹(room)의 사용자가 서로 다른 서버에 접속할 경우, 서버 간 브로드캐스트 전달이 필요해진다. 이를 피하기 위해 그룹 단위 샤딩을 설계했다.
테스트 구성
| 항목 | 설정 |
|---|---|
| 총 사용자 | 100명 |
| 그룹 수 | 2개 (groupId=1, groupId=32) |
| 그룹당 인원 | 50명 |
| 송신자 비율 | 20% (각 그룹 10명) |
| 전송 주기 | 100ms (10Hz) |
| 초당 전송 시도 | 약 200건 |
샤딩 설계
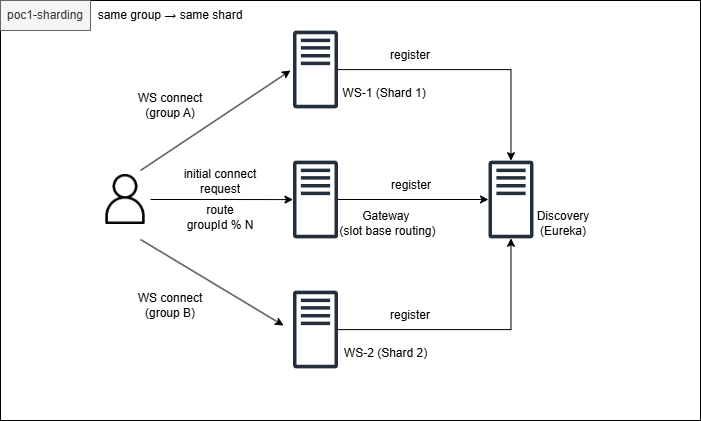
라우팅 공식
slot = groupId % 32
shard = slot / (32 / instanceCount)
동일 groupId는 항상 동일 shard로 매핑 → fanout이 서버 내부에서만 발생
🔍 샤딩 설계와 slot 계산이 실제 부하 분산에 어떻게 영향을 줬는지 전체 분석 보기
원본 분석 노트: GitHub에서 보기
Gateway 라우팅 응답
{
"groupId": 1,
"slot": 1,
"selectedShardId": 1,
"instanceId": "ws-1",
"wsUrl": "ws://ws-1:8082/ws"
}
클라이언트는 연결 전 Gateway에서 wsUrl을 받아 해당 서버로 직접 연결한다.
검증 결과
브로드캐스트 부하 분산
| 구조 | 서버 | totalSendAttempts |
|---|---|---|
| 단일 인스턴스 | ws-1 | 159,317 |
| 샤딩 (2개) | ws-1 | 79,776 |
| 샤딩 (2개) | ws-2 | 79,759 |
- groupId=1 → ws-1, groupId=32 → ws-2 로 정상 분리
- 서버 간 이벤트 전달 없이 각자 내부 broadcast로 처리
JFR / JMC 리소스 분석
| 항목 | Baseline | ws-1 (샤딩) | ws-2 (샤딩) |
|---|---|---|---|
| GC 횟수 | 3회 | 1회 | 1회 |
| Peak Memory | 180 MiB | 176 MiB | — |
| byte[] Allocation | 205 MiB | 93.5 MiB | 111 MiB |
| String Allocation | 33.4 MiB | 19 MiB | 16 MiB |
- 단일 인스턴스에서는 두 그룹의 broadcast가 하나의 JVM에 집중되어 GC가 3회 발생
- 샤딩 적용 후 인스턴스당 GC 1회 수준으로 감소 — 트래픽 분산이 JVM 압력 완화로 직결
핵심 인사이트
그룹 단위 샤딩은 단순 연결 분산이 아니다. fanout locality를 유지하면서 broadcast 처리 부담 자체를 인스턴스 단위로 나눠, JVM Allocation과 GC 횟수까지 함께 줄이는 확장 전략이다.
다음 단계
샤딩으로 부하는 분산했지만, 새로운 문제가 발생한다.
서버가 바뀌는 순간 편집 상태는 어떻게 유지할까?